Spam/Ham Email Classification
UC Berkeley | Data 100
April 2019
|
Behind the scenes, email services such as GMail and Yahoo! have algorithms that classify email as either spam (junk or commercial or bulk) emails from ham (non-spam) emails.
In this project, an machine learning algorithm was created to classify emails as spam or ham. The following methods were used: feature selection, one-hot encoding, natural language processing, and logistic regression. Then, the model was evaluated using a precision-recall curve to achieve and accuracy of 88%. Technologies: Python, pandas, RegEx, Seaborn, Matplotlib, Scikit-Learn |
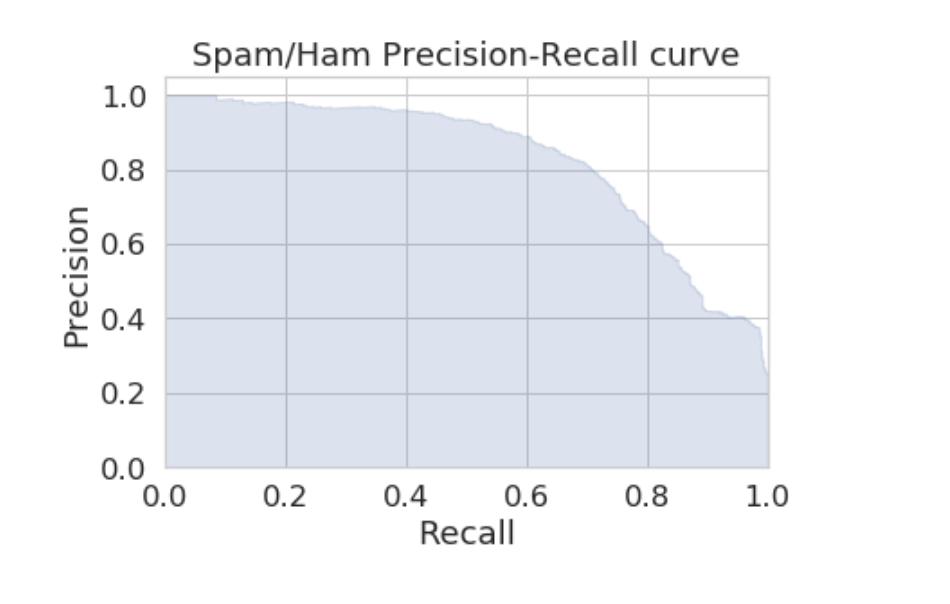
Figure 2.2 A precision-recall curve of the spam/ham email classification machine learning algorithm with 88% accuracy.
|
Twitter Text Analysis
UC Berkeley | Data 100
February 2019
|
Performed natural language processing and sentiment analysis on Twitter text data from Donald Trump. The goals of this project were to analyze Donald Trump's the distribution of tweets over the years using different phones and the distribution of sentiment with varying polarities of certain words.
By removing the HTML tags in a tweet and using the source field, one can make the number of tweets using a certain device in a given year. The tweets acquired were from 2016-2019. One can clearly see that there was a switch from Android to iPhone in 2017. To measure the sentiment of a Tweet, we referenced the VADER (Valence Aware Dictionary and sEntiment Reasoner). This lexicon is a rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media which was great for our usage. Technologies: Python, pandas, RegEx, Seaborn, Matplotlib |
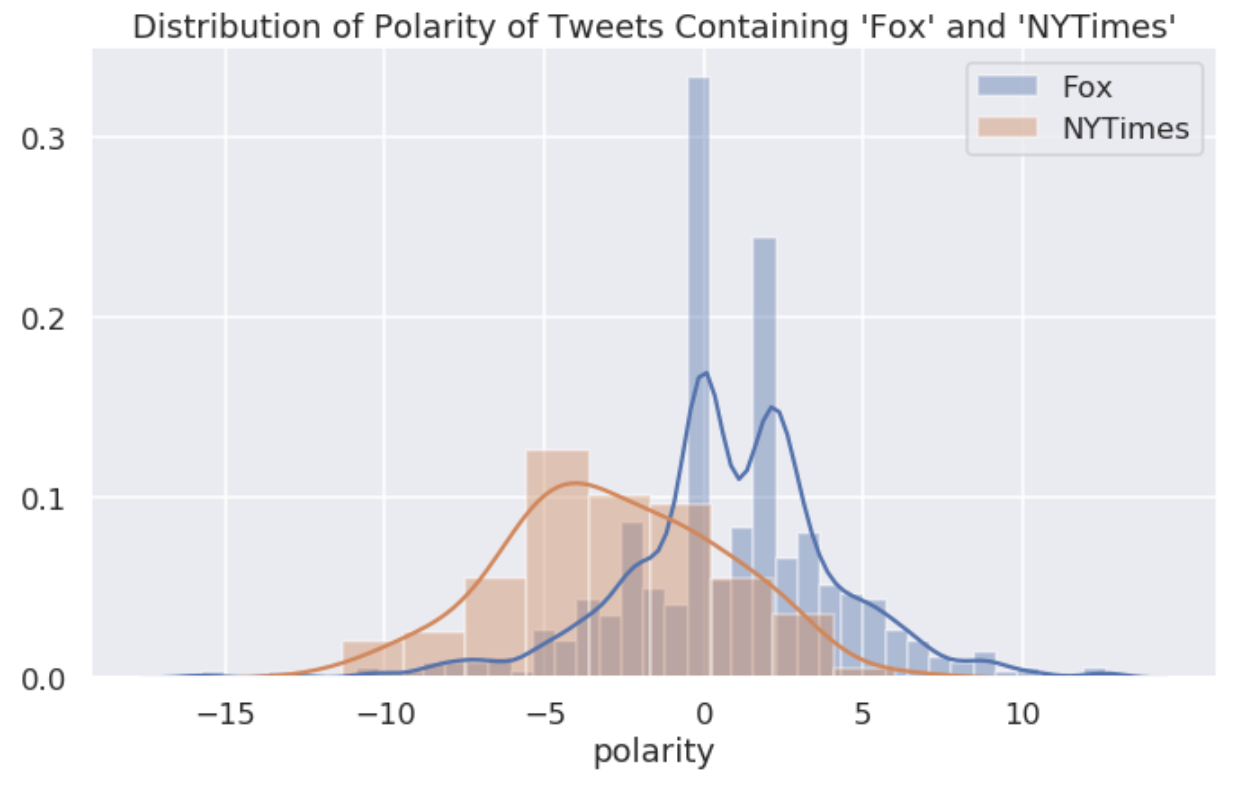
Figure 1.1 Donald Trump has more positive sentiment towards Fox News than New York Times.
|
Food Safety Analysis
UC Berkeley | Data 100
February 2019
|
The San Francisco Department of Public Health evaluates restaurants using Food Safety Score Cards. In this project, exploratory data analysis is performed to understand how restaurants are scored. Some interesting observations were analyzing the distribution of inspection and violation scores, identify missing Zip Code values, and analyzing restaurant ratings over time.
By exploring this data, insight toward working with data at different levels of granularity, exploring characteristics and distributions of individual variables, and applying probability sampling techniques was acquired. Technologies: Python, pandas, Matplotlib |
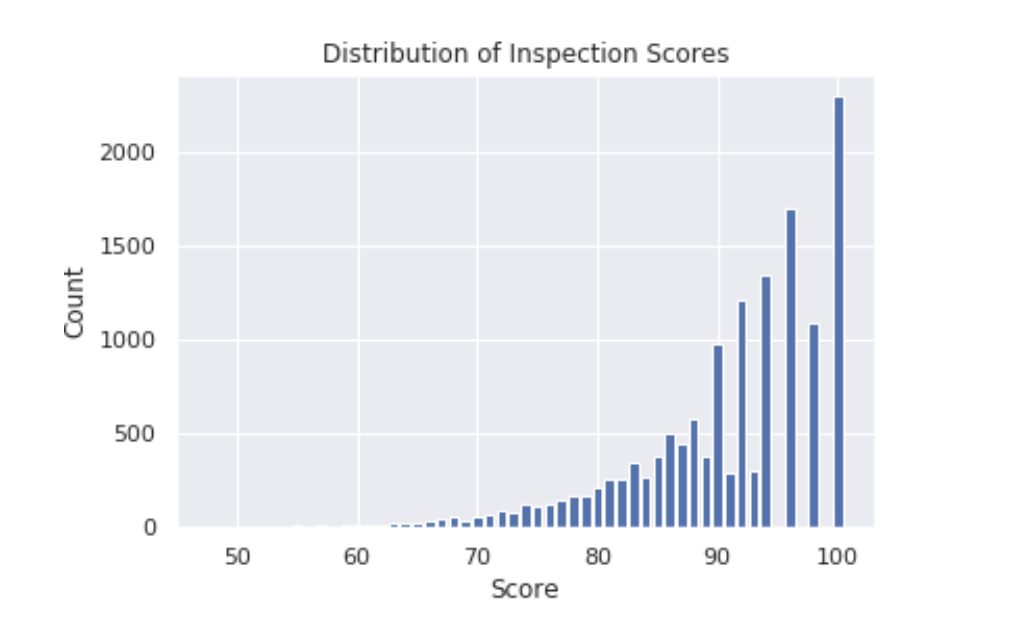
Figure 1.3 Distribution of Inspection Scores according to the San Francisco Department of Public Health.
|
Classifying Movies
UC Berkeley | Data 8
April 2018
|
Through text analysis, one can use machine learning to classify movie screenplays. In this project, we predict a movie's genre from the text of the screenplay. In the dataset, a list of 5,000 words that occurred in conversations between movie character were compiled along with their frequency (how many times that word appears).
Methods to create this model included but are not limited to: k-nearest neighbors, feature engineering, natural language processing, and word stemming. The k-nearest neighbors model was based on the Euclidean Distance and was evaluated using the root mean squared error. An accuracy of 92% was achieved. Technologies: Python, datascience library |
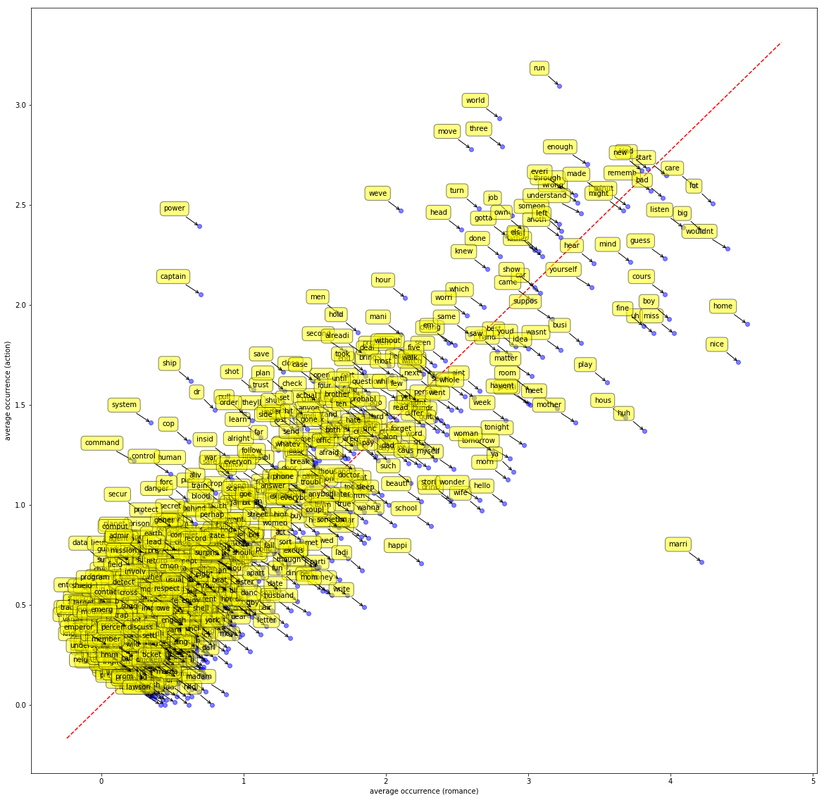
Figure 1.4 The average frequency of each word in romance versus action movies.
|